IEEE CVPR 2024
Real-time Monocular Full-body Capture in World Space via Sequential
Proxy-to-Motion Learning
Yuxiang Zhang1, Hongwen Zhang2*, Liangxiao Hu3, Jiajun Zhang4, Hongwei Yi5, Shengping Zhang3, Yebin Liu1* (* - corresponding author)
1Tsinghua University
2Beijing Normal University
3Harbin Institute of Technology
4Beijing University of Posts and Telecommunications
5Max Planck Institute for Intelligent Systems, T̈ubingen, Germany

Fig 1. The proposed method, ProxyCap, is a real-time monocular full-body capture solution to produce accurate human motions with plausible foot-ground contact in world space.
Abstract
Learning-based approaches to monocular motion cap- ture have recently shown promising results by learning to regress in a data-driven manner. However, due to the chal- lenges in data collection and network designs, it remains challenging for existing solutions to achieve real-time full- body capture while being accurate in world space. In this work, we introduce ProxyCap, a human-centric proxy-to- motion learning scheme to learn world-space motions from a proxy dataset of 2D skeleton sequences and 3D rotational motions. Such proxy data enables us to build a learning- based network with accurate world-space supervision while also mitigating the generalization issues. For more accu- rate and physically plausible predictions in world space, our network is designed to learn human motions from a human-centric perspective, which enables the understand- ing of the same motion captured with different camera tra- jectories. Moreover, a contact-aware neural motion descent module is proposed in our network so that it can be aware of foot-ground contact and motion misalignment with the proxy observations. With the proposed learning-based solu- tion, we demonstrate the first real-time monocular full-body capture system with plausible foot-ground contact in world space even using hand-held moving cameras.
Overview
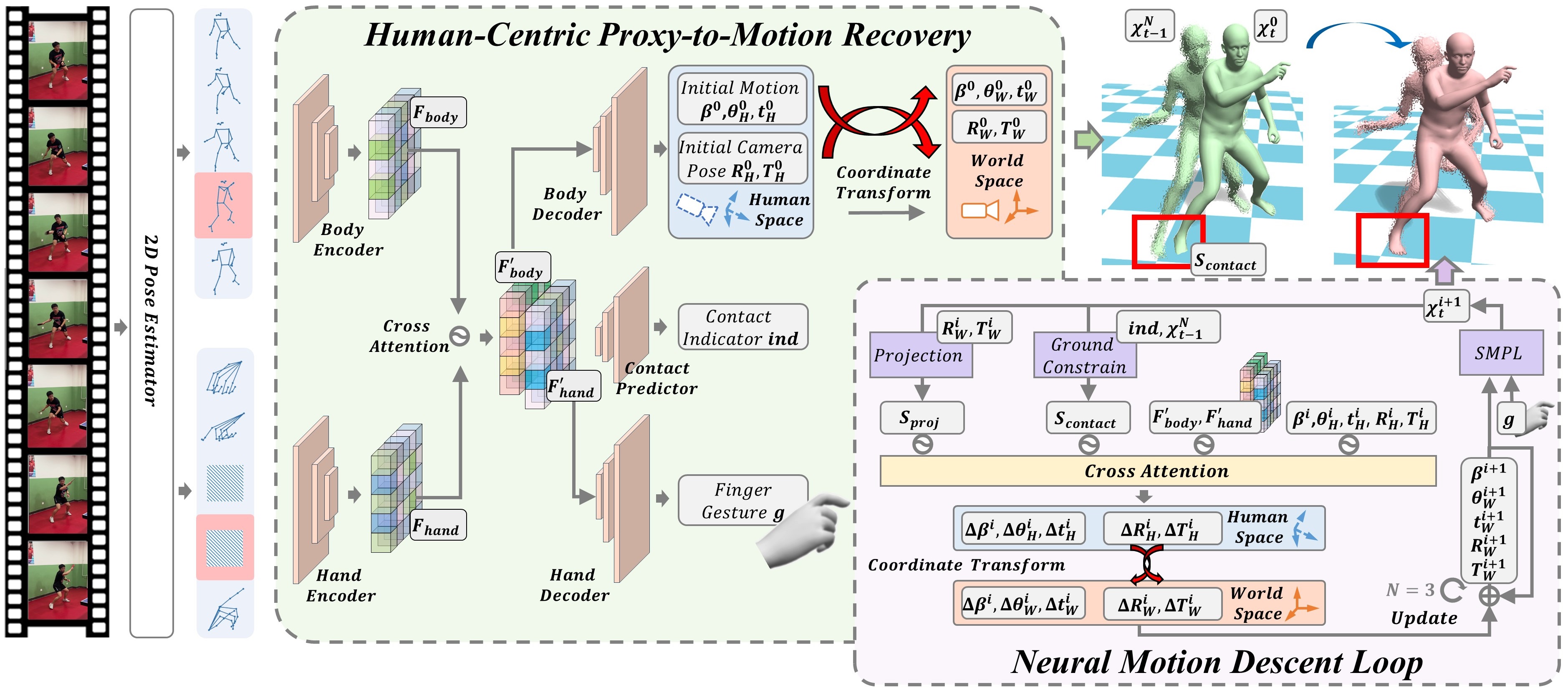
Fig 2. Illustration of the proposed method ProxyCap. Our method takes the estimated 2D skeletons from a sliding window as inputs and estimates the relative 3D motions in the human coordinate space. These local movements are accumulated frame by frame to recover the global 3D motions. For more accurate and physically plausible results, a contact-aware neural motion descent module is proposed to refine the initial motion predictions.
Results

Fig 3. Results across different cases in the (a,g) 3DPW [61], (b) EHF [40], and (c) Human3.6M [13] datasets and (d,e,f) internet videos. We demonstrate that our method can recover the accurate and plausible human motions in moving cameras at a real-time performance. Specifically, (g) demonstrates the robustness and the temporal coherence of our method even under the occlusion inputs.
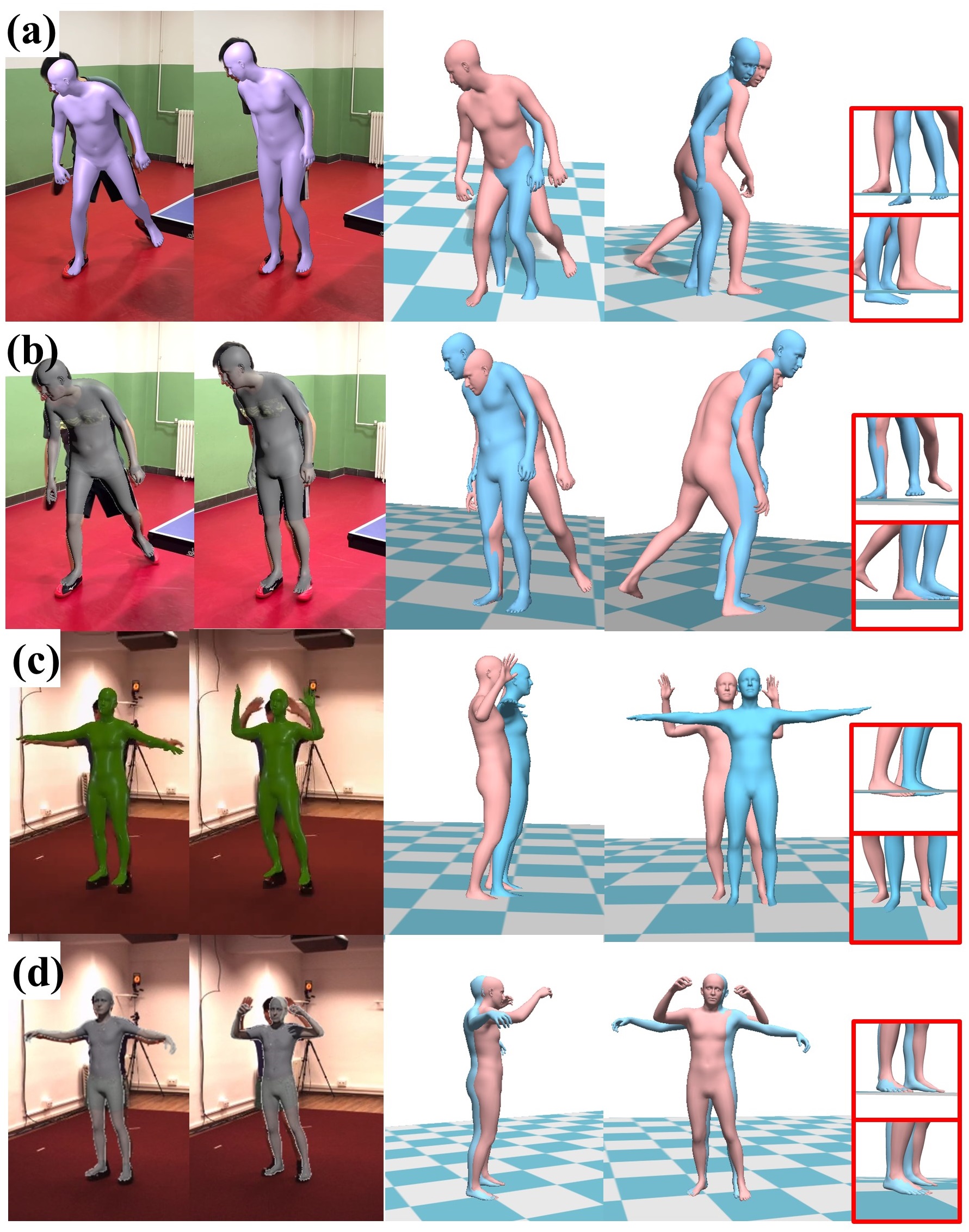
Fig 4. Qualitative comparison with previous state-of-the-art methods: (a) PyMAF-X [72], (c) GLAMR [67], (b)(d) Ours.
Technical Paper

Demo Video
Citation
Yuxiang Zhang and Hongwen Zhang and Liangxiao Hu and Jiajun Zhang and Hongwei Yi and Shengping Zhang and Yebin Liu. "ProxyCap: Real-time Monocular Full-body Capture in World Space via Human-Centric Proxy-to-Motion Learning"
@misc{zhang2023proxycap,
title={ProxyCap: Real-time Monocular Full-body Capture in World Space via Human-Centric Proxy-to-Motion Learning},
author={Yuxiang Zhang and Hongwen Zhang and Liangxiao Hu and Jiajun Zhang and Hongwei Yi and Shengping Zhang and Yebin Liu},
year={2023},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition, (CVPR)},
}